[Split Learning] 기본 구조
`Split Learning`의 첫번째 포스팅입니다.
Split Learning
Federated Learning (FL)은 여러 기관이 원시 데이터를 공유하지 않고도 협업할 수 있도록 하는 학습 전략입니다. FL은 구조적으로 분산된 데이터를 학습하기 때문에, 단일 머신에서의 학습 결과와는 다소 차이가 발생할 수밖에 없습니다. 이에 비해 Split Learning (SL)은 FL과 마찬가지로 원시 데이터를 공유하지 않으면서도 단일 머신에서의 학습과 동일한 결과를 얻을 수 있도록 하는 새로운 접근 방식을 제시합니다.
SL에 대해 공부하기 전에는, 'Split'이라는 단어가 무엇을 쪼갠다는 의미인지 쉽게 감이 오지 않았습니다. 데이터를 쪼갠다는 의미일까? 그렇다면 샘플을 쪼개는 것인지, 아니면 피처를 쪼개는 것인지? 데이터를 숨겨서 전송하는 것일 텐데, 그 과정에서 어떻게 쪼개진다는 것인지 여러 생각이 들면서 논문을 읽기 시작했습니다.
우선 SL은 FL이 제시된 몇 년 후, MIT에서 처음 제안된 방법입니다.

구조
Vanilla 구조
이 방법에서 'Split'이라는 용어는 데이터가 아닌, 모델을 쪼갠다는 의미입니다. SL 모델의 가장 기본적인 형태는 다음과 같습니다.
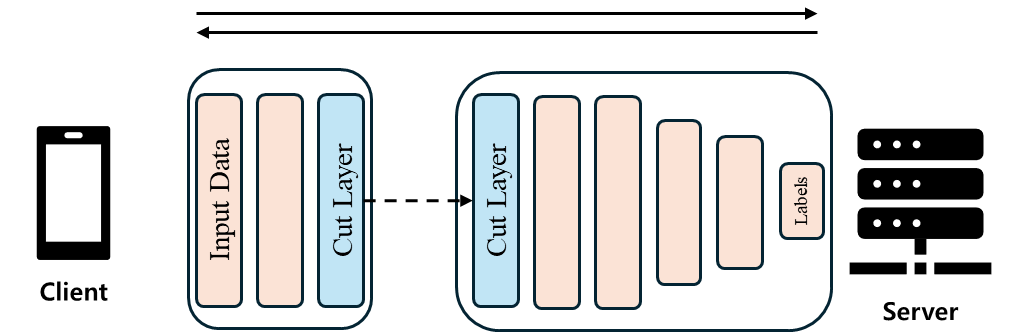
이 방법은 모델을 client-side와 server-side로 나누는데, client-side에서는 모델의 앞단 일부만 학습하고, server-side로 보내어 모델의 뒷단, 즉 더 깊은 부분을 학습시킵니다. 이때 모델이 나뉘는 층을 'cut layer'라고 부르며, 이 층의 활성화 값을 'smashed data'라고 합니다. 이 smashed data를 client와 server가 주고받으며 학습을 진행합니다. 구체적인 절차는 다음과 같습니다.
- Client-side에서 forward propagation을 통해 cut layer까지 학습합니다.
- Cut layer를 server로 보냅니다.
- Server-side에서 forward propagation을 통해 loss를 계산합니다.
- Server-side에서 back propagation을 통해 cut layer까지 전달합니다.
- Gradient를 client-side로 보냅니다.
- Client-side에서 back propagation을 마치고 weight를 업데이트합니다.
- 이 과정을 모델이 수렴할 때까지 반복합니다
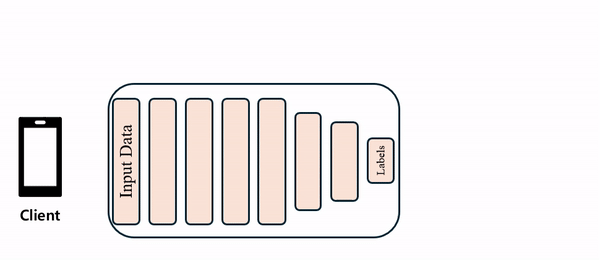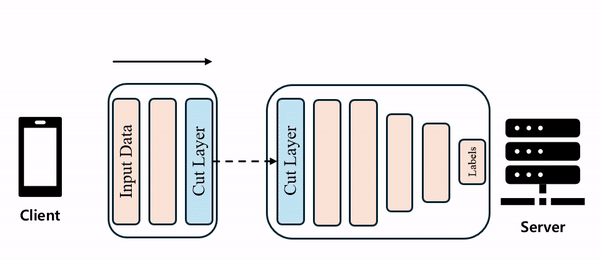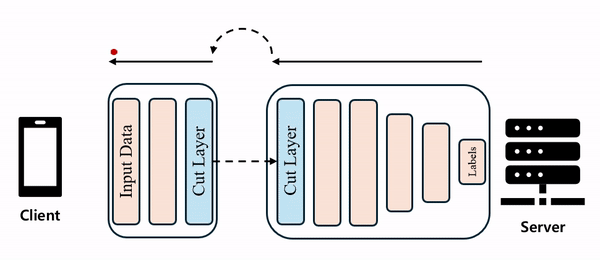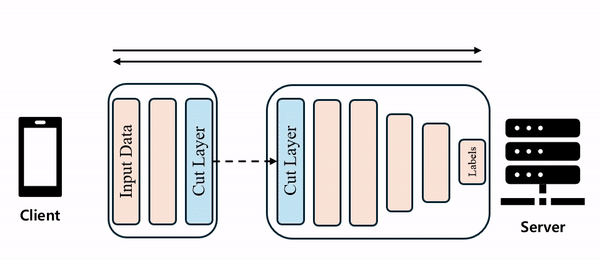

이러한 기본 구조의 장점은 client-side의 연산 부담이 줄어들고, 원시 데이터가 아닌 cut layer(또는 smashed data)를 전송하기 때문에 보안 측면에서도 유리하다는 점입니다.