`Hadoop: The Definitive Guide (4th Edition)` 정리 내용입니다.

데이터 시대
우리는 데이터 시대에 살고있습니다. 전체 데이터 양을 측정하기는 어렵지만, 대략적으로 2013년에 4.4 제타바이트였으며, 2020년에는 그 10배인 약 44 제타바이트정도가 될 것이라 추정합니다(1 제타바이트 = 10억 테라비이트). 이런 홍수와도 같은 데이터 양은 여러 소스로부터 생깁니다. 예를들어, 뉴욕 주식 시장은 매일 4-5 테라바이트의 데이터를 생성하고, 페이스북 또한 1달에 2400억 사진으로 약 7 페타바이트를 호스팅합니다.
"더 많은 데이터가, 더 나은 알고리즘보다 났다" 라는 말이 있습니다. 데이터의 양으로 정교한 알고리즘을 넘어설 수 있다는 이야기이죠. 좋은 소식은 이미 많은 양의 데이터가 있다는 것이고, 나쁜소식은 이걸 저장하고 분석하는데 어려움을 겪고 있다는 사실입니다.
데이터 저장과 분석
문제는 하드의 저장 카파가 수년동안 걸쳐 엄청나게 증가했지만, 드라이브에서 데이터를 읽는 속도(access speeds)는 그에 미치지 못하게 증가했다는 것입니다. 1990년대의 일반적인 드라이브는 1,370MB의 데이터를 저장할 수 있었고, 전송 속도는 4.4MB/s였습니다. 따라서 전체 드라이브의 모든 데이터를 약 5분 안에 읽을 수 있었지만, 최근의 일반적인 1 테라바이트 드라이브의 전송 속도는 100MB/s로 디스크에서 모든 데이터를 읽는데 2.5시간이 넘게 소요됩니다.

여기서 시간을 줄이는 확실한 방법은 여러 디스크에서 동시에 읽는 것입니다. 예를 들어, 각각 데이터의 100분의 1을 저장하는 100개의 드라이브가 있다고 상상해 본다면, 병렬로 작업하시 2분 안에 데이터를 읽을 수 있습니다. 디스크의 100분의 1만 사용하는 것은 낭비처럼 보일 수 있지만, 각각의 사용자가 1 테라바이트인 100개의 데이터 세트를 나누어 저장하고 공유 액세스를 제공한다면, 이야기는 달라집니다. 사용자의 입장에서, 분석 시간을 단축하는 대가로 기꺼이 액세스를 공유할 것입니다. 또한, 분석 작업 시간이 겹칠 가능성이 낮기 때문에 서로에게 큰 영향을 미치지 않을 것입니다.
그치만, 이러한 병렬 상황에서 데이터를 read/write하는 데에는 더 많은 고려사항이 있습니다.
먼저 하드웨어 failure입니다. 많은 하드웨어 부품을 사용하면, 그중 하나의 고장 가능성은 많이 높아집니다. 이러한 failure의 경우 데이터가 손실 될 수도 있는데, 이를 복제로 해소합니다. 예를들어, 복사본을 저장하며 디바이스에서 failure 발생 시 다른 복사본을 사용할 수 있게 하는 방식입니다.
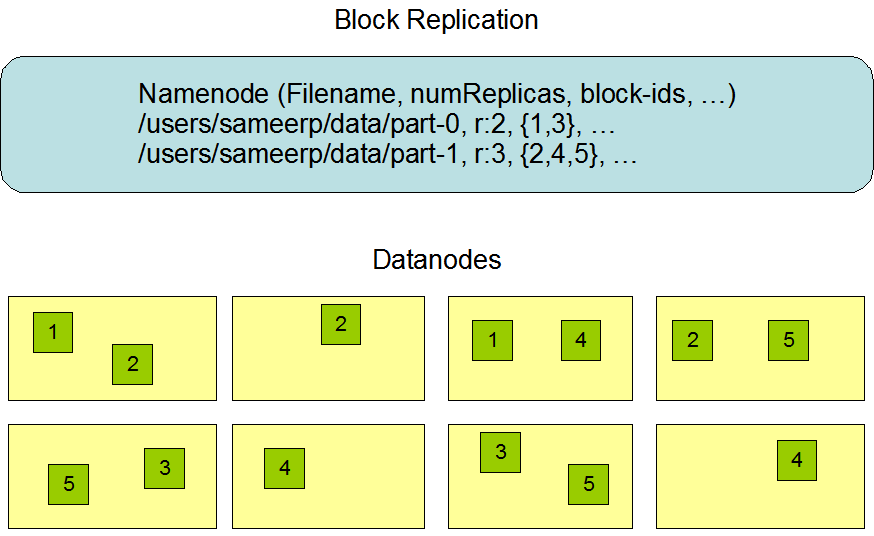
두번째 문제는 대부분의 분석작업은 어떤 방식으로던 데이터와 결합 가능해야한다는 것입니다. 예를들어, 한 디스크에서 읽은 데이터는 다른 99개의 디스크 중 어느 것의 데이터와도 결합해야 할 수 있어야합니다. 다양한 분산 시스템이 여러 출처의 데이터를 결합하는 것을 허용하지만, 이를 올바르게 수행하는 것은 매우 어렵다고 알려져 있습니다. `맵리듀스(MapReduce)`는 디스크 read/write문제를 추상화하여 키와 값의 집합에 대한 연산으로 변환하는 모델을 제시합니다.

쿼리
일반적인 관계형 데이터베이스는 특정 데이터를 효율적으로 찾기 위해 인덱스를 사용합니다. 반면, 맵리듀스는 쿼리의 종류에 관계없이 기본적으로 전체 데이터셋을 처음부터 끝까지 탐색하는 방식을 취하는 경우가 많습니다. 이러한 접근은 마치 모든 경우의 수를 다 확인하는 무차별 대입(Brute-force) 방식처럼 보일 수 있습니다.
하지만 이러한 특징이 분산 처리 시스템에서는 오히려 강력한 장점으로 작용합니다. 전통적인 인덱싱 방식은 미리 정의되거나 예측 가능한 쿼리에 대해서는 매우 효율적입니다. 그러나 데이터의 구조가 매우 복잡하거나 비정형적이어서 인덱스 생성이 어렵거나, 예상치 못한 다양한 쿼리(ad-hoc query)에 답해야 하는 상황에서는 한계를 드러낼 수 있습니다.
맵리듀스는 바로 이런 상황에서 강점을 보입니다. 전체 데이터를 대상으로 작업을 수행하기 때문에, 사전에 완벽히 구조화되지 않은 데이터나 예측하지 못했던 쿼리에 대해서도 분석을 시도하고 의미 있는 결과를 도출해낼 수 있는 유연성을 제공합니다. 물론 이는 대규모 데이터를 병렬로 처리할 수 있는 분산 환경이 뒷받침되기에 가능한 일입니다.
배치 처리
맵리듀스는 여러 강점에도 불구하고, 근본적으로 배치처리 시스템이며, 상호작용이 필요한 분석에는 적합하지 않습니다. 쿼리를 실행하고는 즉각적인 리턴을 받을 수 없음으로 즉각적인 반응을 반영하는 온라인 작업보다는 오프라인 작업에 적합합니다. 하지만, 하둡은 이러한 한계를 보이는 초기의 모습에서 발전하여 분산 컴퓨팅 및 대규모 데이터 처리를 위한 여러 하둡 생태계를 구성하였습니다.
예를들어, 온라인 액세스를 가능하게 하는 첫 구성 요소는 `HBase`로, 기본 스토리지로 `HDFS`를 사용하는 key-value 저장소 입니다. HBase는 개별 행에 대한 온라인 read/write 저장소로, 대용량 데이터의 read/write 액세스와 배치 작업을 모두 제공합니다. 추가로 새로운 모델을 처리 가능하도록 하는 진짜 원동력은 `YARN(Yet Another Resource Negotiator)`에 있습니다. 이 방식은 클러스터 자원 관리 시스템으로, 맵리듀스를 포함한 모든 분산 프로그램이 하둡 클러스터의 데이터에서 실행될 수 있도록 허용합니다.
기타
첫 챕터에서는 이 외에도 데이터를 계산 작업이 이루어 지는 곳 가까이 두는 data locality를 이용해 네트워크 병목을 줄인다는 이야기. 시스템이 자동로 에러를 복구해줘 관리에 부담이 줄어든다는 특성. 전 세계의 개인 PC의 남는 자원을 사용하는 volunteering과는 다른, 자체 구성 클러스터 내에서의 조작에 최적화 되어있다는 이야기. 그리고 하둡의 간략한 야후와의 역사, 앞으로 책에서 다룰 내용에 대하여 소개합니다.
출처
Book, "Hadoop: The Definitive Guide"
https://web.cs.ucla.edu/classes/winter13/cs111/scribe/10c/
Lecture 10 - File System Performance
Mean Time Before Failure (MTBF) the estimated time before the device fails. Note: 2,000,000 hours is over 200 years! Obviously the devices were not tested for this long, so this number is a very rough estimate. 2,700,000 hours 2,000,000 hours
web.cs.ucla.edu
https://hadoop.apache.org/docs/r3.3.2/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
Apache Hadoop 3.3.2 – HDFS Architecture
<!--- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or a
hadoop.apache.org
https://www.sunlab.org/teaching/cse8803/fall2016/lab/mapreduce-basic/
MapReduce Basics - Bigdata Bootcamp
You can achieve this by updating mapper as public void map(LongWritable offset, Text lineText, Context context) throws IOException, InterruptedException { String line = lineText.toString(); String eventID = line.split(",")[1]; if(eventID.startsWith("DIAG")
www.sunlab.org