지난 글 `[SplitFed] 개념`에 이어지는 내용입니다.
구조
SplitFed(SFL)는 이름에서 알 수 있듯이, Split Learning(SL)과 Federated Learning(FL)을 결합한 방식입니다. 이 방법의 가장 큰 특징은 두 개의 서버를 사용한다는 점입니다. 하나는 FL을 위한 `fed server`, 다른 하나는 SL을 위한 `main server`로, 그림상 각각 `server2`와 `server1`에 해당됩니다. 주된 학습은 `server1`에서 이루어지기 때문에 이를 `main server`라 부릅니다.
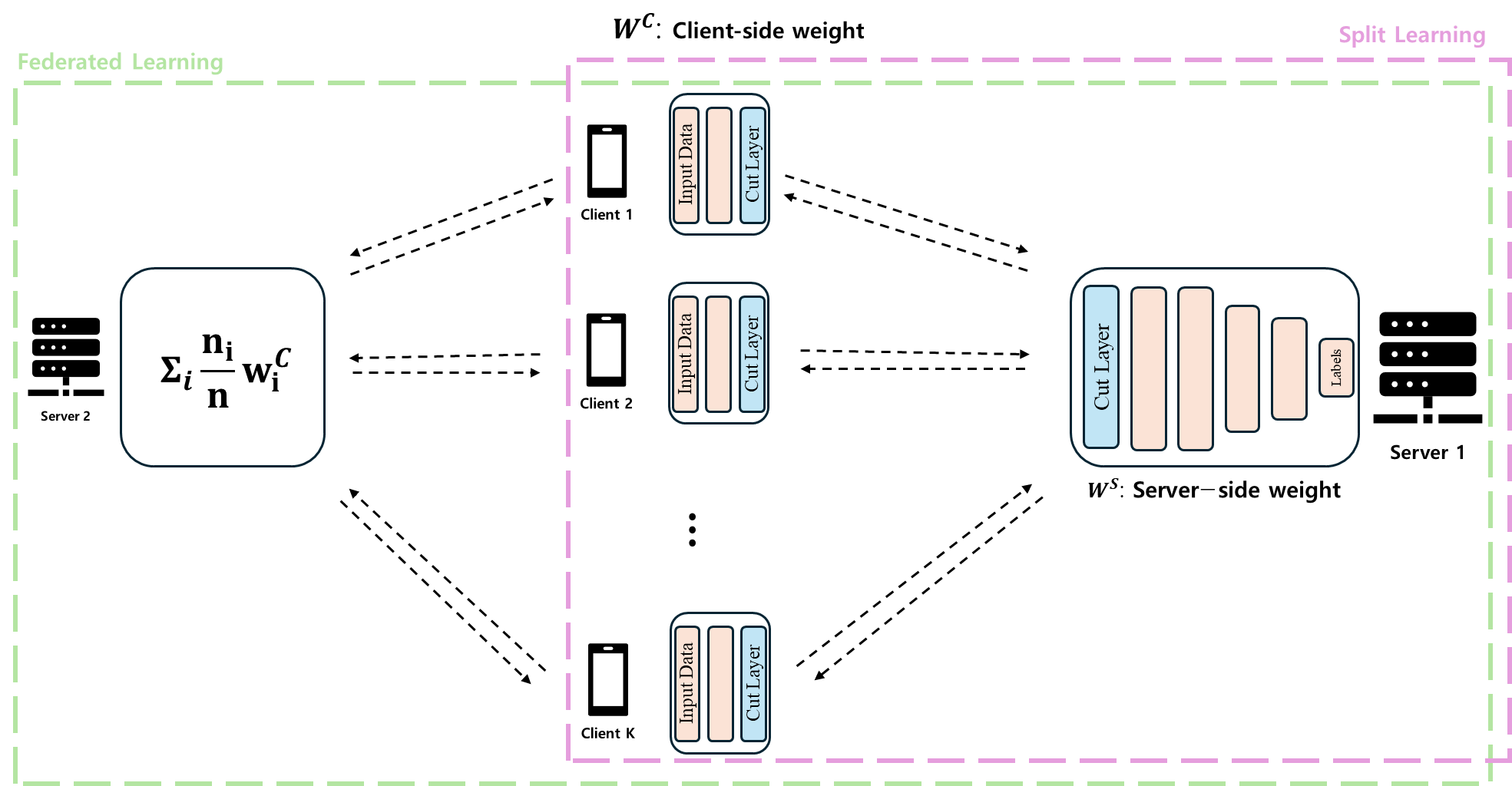
SFL에서 모델을 업데이트하는 방식은 FL의 방식을 차용하며, 계산의 효율성과 구조적인 보안성을 고려하여 SL도 활용합니다.
먼저 SL 부분을 살펴보면, SFL은 기존 SL의 모델을 쪼개어 서버에서 학습한다는 아이디어만을 빌려왔습니다. 기존의 SL은 sequential하게 학습이 이루어져 overhead가 발생하고, 그로 인해 학습 시간이 오래 걸리는 특징이 있었습니다. 그러나 SFL의 SL 부분은 다른 클라이언트의 학습을 기다리지 않고, 병렬적으로(parallel) 클라이언트를 학습시키며, 동시에 정보를 aggregation 합니다. 이는 두 개의 서버를 사용하는 구조 덕분에 가능하며, 구체적으로는 `fed server`에서 한 번에 모델을 업데이트 겸 aggregation을 수행하기 때문에 학습 시간을 단축할 수 있습니다.
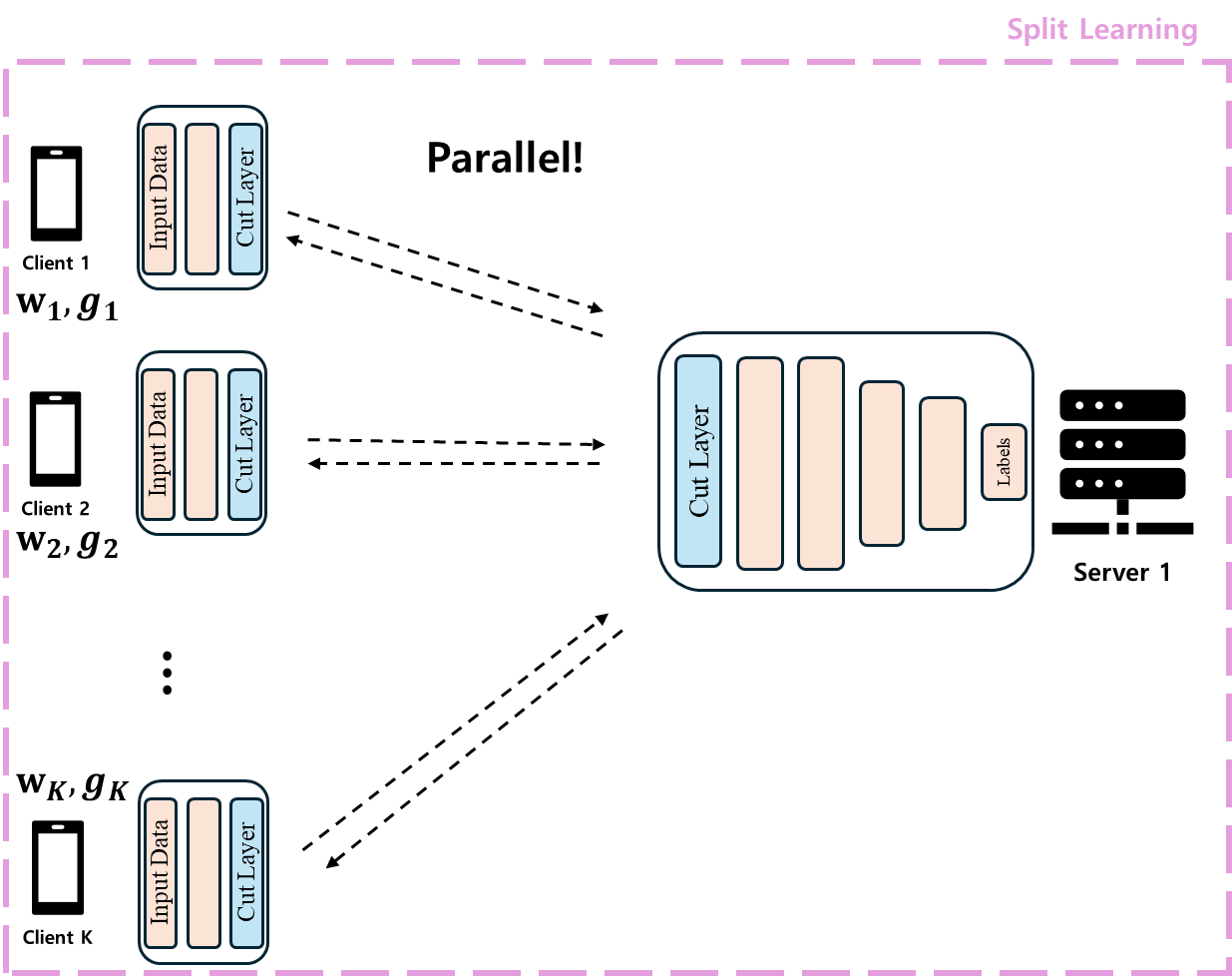
다음으로 FL 부분을 살펴보면, SFL의 FL 역시 기존 FL과 차이를 보입니다. 이는 SL 부분에서 모델이 client-side와 server-side로 나뉘기 때문에 발생하는데, FL이 두 부분에서 일어납니다. 여기서 server-side는 gradient를 사용해 새로운 weight를 업데이트하며, client-side는 weight의 가중평균으로 업데이트를 합니다. 논문에서는 `FedAVG` 알고리즘을 사용한다고 명시하고 있지만, 어떤 업데이트 알고리즘을 사용해도 무방할 것으로 보입니다.
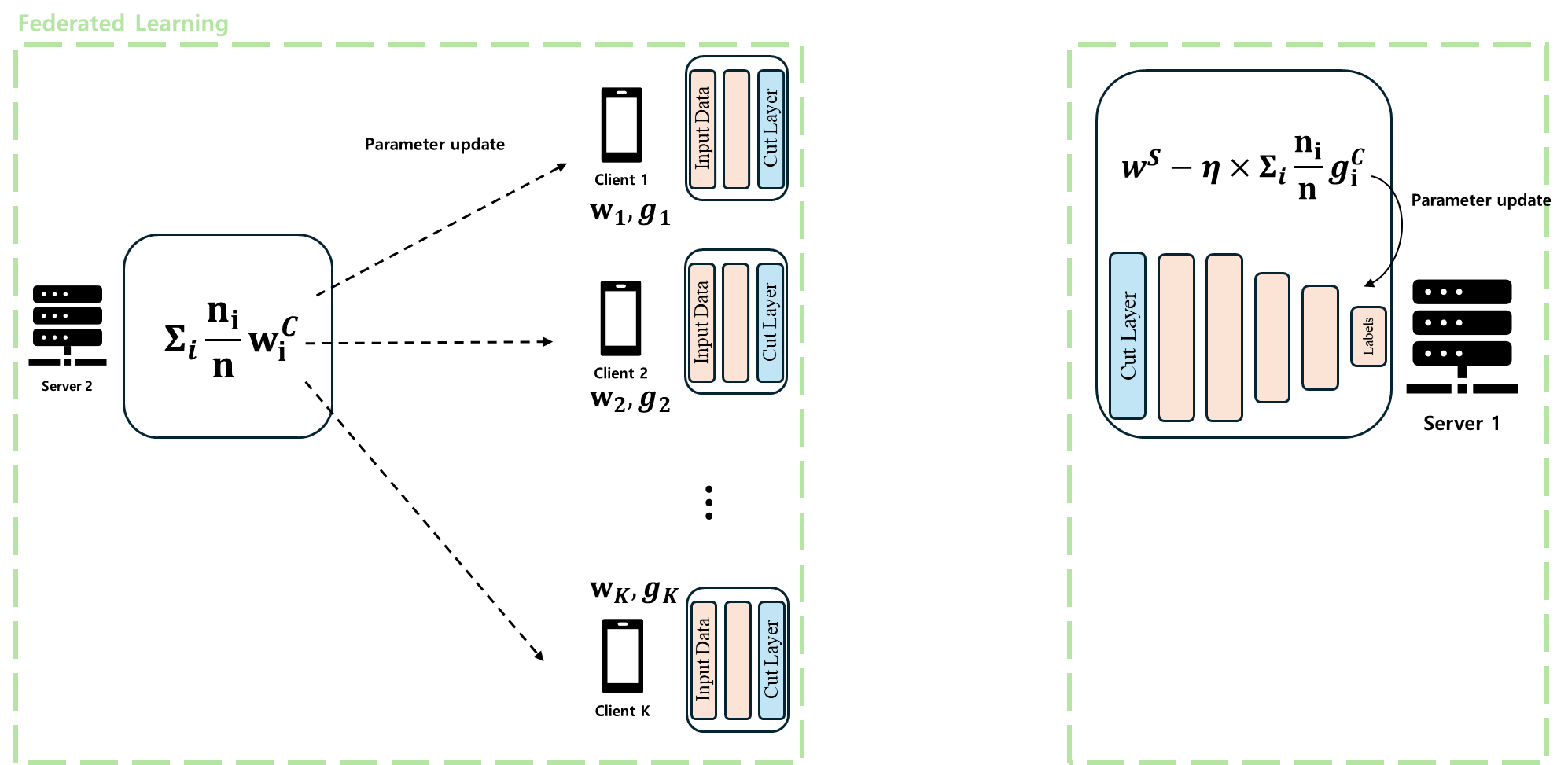
하지만 이렇게 병렬적으로 학습을 진행하면, SL의 장점인 "모든 cut layer의 학습 참여로 인한 성능 향상"을 이룰 수 없습니다. 이를 보완하기 위해 server-side 모델 업데이트 시 `FedAVG`와 같은 FL 방식을 사용하지 않고, 랜덤으로 cut layer를 하나씩 비복원 추출하여 서버로 보내 forward & backward propagation을 진행하여 업데이트하는 방식도 소개되고 있습니다.

SFL에서는 이러한 방식을 두 가지로 구분합니다. 병렬적인 학습 방식은 `SFLV1`, 다소 순차적인 방식은 `SFLV2`라 부릅니다. 아래의 알고리즘은 `SFLV1`에 대한 내용을 담고 있습니다.


각 과정을 시각화하여 보자면, 아래와 같습니다.


비교
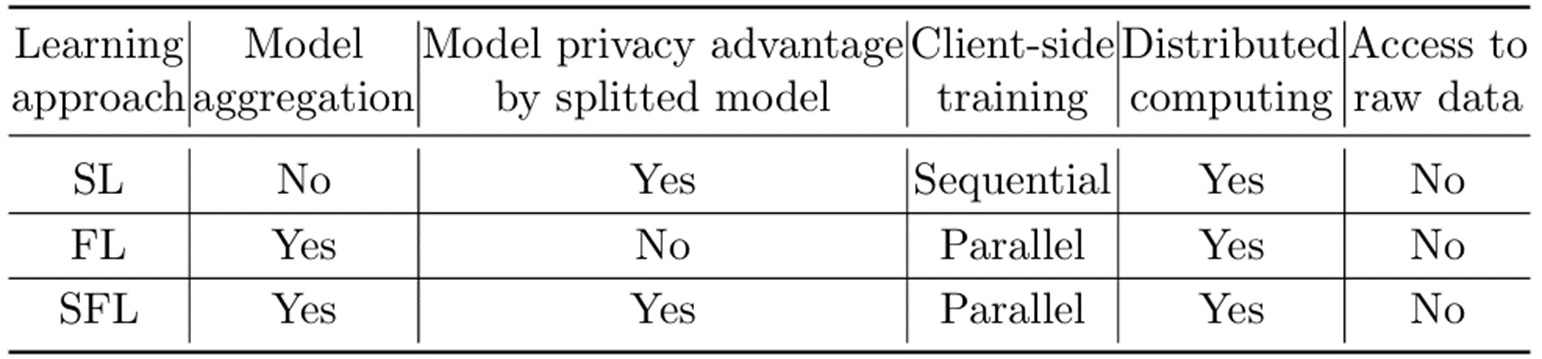
아래의 표는 FL, SL, 그리고 SFL 방법론의 기능을 비교한 것입니다. 당연한 이야기지만, 정리해보면 SFL이 FL과 SL의 장점을 잘 결합한 방식임을 확인할 수 있습니다. 다만, 중요한 server-side 학습이 부분적으로 병렬적인 방식으로 이루어진다는 정보는 포함되지 않았습니다.
'통계 & 머신러닝 > 연합학습' 카테고리의 다른 글
| [FedProx] 등장 배경 (0) | 2024.11.22 |
|---|---|
| [SplitFed] 결과 (0) | 2024.08.11 |
| [SplitFed] 개념 (0) | 2024.08.11 |
| [Split Learning] 결과 (0) | 2024.08.11 |
| [Split Learning] 응용 구조 (0) | 2024.08.11 |