`Torch Uncertainty` 공식문서의 `Quick Start`를 번역 및 정리한 내용입니다.
Torch Uncertainty는 Pytorch Lightning을 기반으로 작성되어, Pytorch model을 Routine이라는 객체로 상속받아 Pytorch Lightning을 구현한것 처럼 사용 가능합니다.

Torch Uncertainty
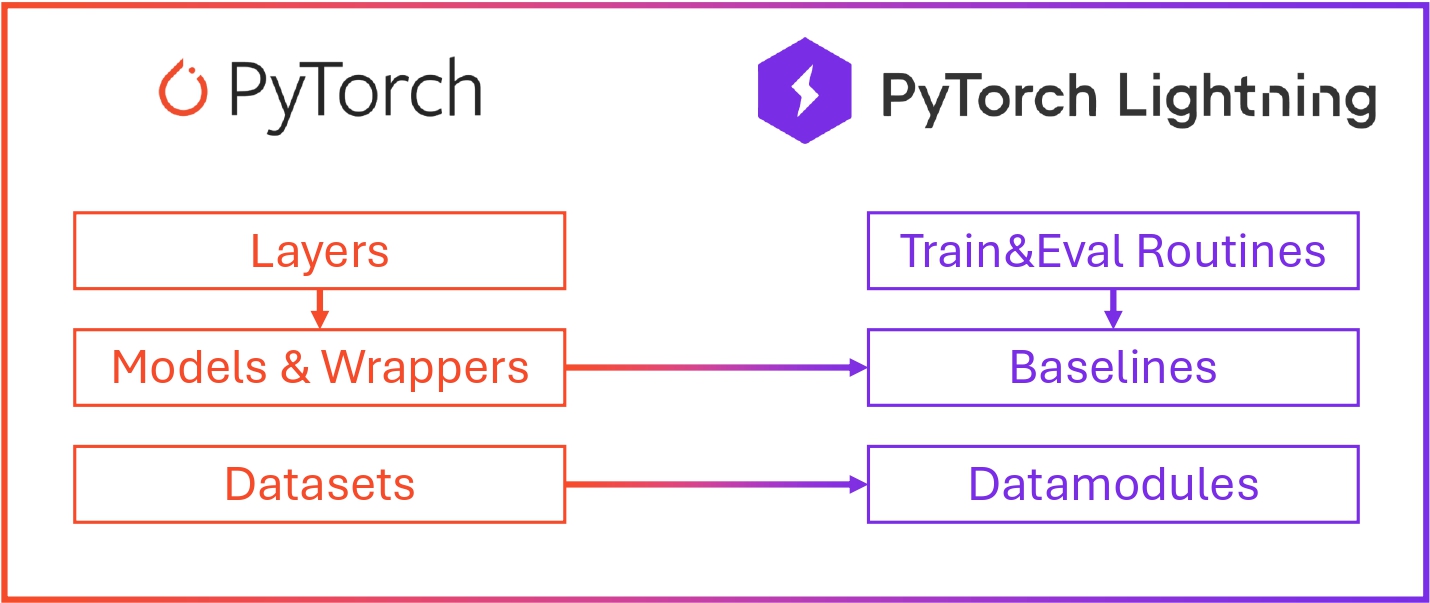
TorchUncertainty는 PyTorch 기반의 라이브러리로, 불확실성(Uncertainty)을 고려한 훈련 및 평가를 간편하게 수행할 수 있도록 설계되었습니다. 이 라이브러리는 특히 다양한 앙상블 기법(Deep Ensembles, Packed-Ensembles, MIMO, Masksembles 등)을 지원하며, 모델의 불확실성을 측정하고 모니터링할 수 있는 기능을 제공합니다. 또한, 평가 시 캘리브레이션 방법을 자동으로 적용할 수 있어, 모델의 성능을 더 정확하게 평가할 수 있습니다.
Training with TorchUncertainty’s Uncertainty-aware Routines
TorchUncertainty의 주요 기능 중 하나는 `ClassificationRoutine` 클래스입니다. 이 클래스는 사용자 정의 모델을 포함한 다양한 PyTorch 모델을 손쉽게 훈련하고 평가할 수 있도록 도와줍니다. `ClassificationRoutine`을 사용하면, 모델의 손실 함수와 최적화 방법을 지정할 수 있으며, 불확실성 측정과 관련된 다양한 옵션을 설정할 수 있습니다.
from lightning.pytorch import LightningModule
class ClassificationRoutine(LightningModule):
def __init__(
self,
model: nn.Module,
num_classes: int,
loss: nn.Module,
num_estimators: int = 1,
format_batch_fn: nn.Module | None = None,
optim_recipe: dict | Optimizer | None = None,
# ...
eval_ood: bool = False,
eval_grouping_loss: bool = False,
ood_criterion: Literal[
"msp", "logit", "energy", "entropy", "mi", "vr"
] = "msp",
log_plots: bool = False,
save_in_csv: bool = False,
calibration_set: Literal["val", "test"] | None = None,
) -> None:
...이 루틴은 사용자 정의 모델이나 TorchUncertainty 분류 모델을 감싸는 래퍼(wrapper) 역할을 합니다. 사용 방법은 간단합니다. 먼저 모델을 구축한 후, 이 모델을 루틴에 전달합니다. 이때 최적화 방법(optimization recipe), 손실 함수(loss), 그리고 모델의 클래스 수를 함께 전달하면 됩니다. 이러한 구성 요소를 통해 TorchUncertainty의 다양한 지표를 활용한 모델 평가가 가능합니다.
Building your First Routin
from torch import nn, optim
model = MyModel(num_classes=10)
routine = ClassificationRoutine(
model,
num_classes=10,
loss=nn.CrossEntropyLoss(),
optim_recipe=optim.Adam(model.parameters(), lr=1e-3),
)이 루틴을 사용해 모델을 훈련하려면, 먼저 Lightning Trainer를 생성하고, Lightning Datamodule 또는 PyTorch Dataloader가 필요합니다. 모델의 벤치마킹 시에는 Lightning Datamodule을 사용하는 것을 권장합니다. 이는 자동으로 훈련, 검증, 테스트 세트를 나누고, Out-of-Distribution(OOD) 탐지와 데이터셋 변화를 처리하기 때문입니다. 예를 들어, TorchUncertainty의 CIFAR10 Datamodule을 사용할 수 있습니다.
Training with the Routine
from torch_uncertainty.datamodules import CIFAR10DataModule
from lightning.pytorch import Trainer
dm = CIFAR10DataModule(root="data", batch_size=32)
trainer = Trainer(gpus=1, max_epochs=100)
trainer.fit(routine, dm)
trainer.test(routine, dm)이제 TorchUncertainty를 사용해 첫 번째 모델을 훈련했습니다! 그 결과, 모델이 불확실성을 처리하는 능력을 측정할 수 있는 다양한 지표에 접근할 수 있게 됩니다. Lightning Trainer를 사용한 다른 훈련 예시는 튜토리얼에서 확인할 수 있습니다.
TorchUncertainty의 Datamodule을 사용하면 OOD 데이터셋에서 모델을 쉽게 테스트할 수 있습니다. 이를 위해 `eval_ood` 파라미터를 True로 설정하면 됩니다. 또한, `eval_grouping_loss` 파라미터를 `True`로 설정하여 그룹 손실을 평가할 수도 있습니다. 마지막으로, `calibration_set` 파라미터를 사용해 모델을 보정할 수 있습니다. 이 경우, 보정되지 않은 모델과 보정된 모델 모두에 대한 지표를 얻을 수 있으며, Temperature Scaling된 모델의 지표는 `ts_`로 시작합니다.
또한, 라이브러리는 Lightning CLI 도구를 활용하여 실험의 재현성을 높이고, 구성 파일을 통해 실험 설정을 체계적으로 관리할 수 있습니다. 이를 통해 실험의 복잡성을 줄이고, 실험 결과의 일관성을 유지할 수 있습니다.
Lightning을 사용하지 않고도 클래식한 PyTorch 방식으로 모델을 훈련하고 평가할 수 있습니다. 필요에 따라 제공되는 레이어를 조합해 원하는 아키텍처를 직접 구현할 수 있습니다.
참조
https://torch-uncertainty.github.io/quickstart.html
Quickstart — TorchUncertainty 0.2.1.post0 documentation
Quickstart TorchUncertainty is centered around uncertainty-aware training and evaluation routines. These routines make it very easy to: train ensembles-like methods (Deep Ensembles, Packed-Ensembles, MIMO, Masksembles, etc) compute and monitor uncertainty
torch-uncertainty.github.io
'통계 & 머신러닝 > 통계적 머신러닝' 카테고리의 다른 글
| [Torch Uncertainty] Tutorial: Training a LeNet with Monte-Carlo Dropout (0) | 2024.08.22 |
|---|---|
| [Torch Uncertainty] Tutorial: Improve Top-label Calibration with Temperature Scaling (0) | 2024.08.22 |
| [Torch Uncertainty] Installation (0) | 2024.08.22 |
| [논문] On Calibration of Modern Neural Networks: Results (0) | 2024.08.20 |
| [논문] On Calibration of Modern Neural Networks: Calibration (0) | 2024.08.20 |