`Torch Uncertainty` 공식문서의 `Tutorials`를 번역한 내용입니다.

Improve Top-label Calibration with Temperature Scaling
이 튜토리얼에서는 TorchUncertainty를 사용하여 top-label 예측의 캘리브레이션을 개선하고, 기본 신경망의 신뢰성을 향상시키는 방법을 다룹니다.
이 튜토리얼에서는 `TemperatureScaler` 클래스를 사용하는 방법에 대한 자세한 내용을 제공하지만, 이는 분류 루틴에서 `calibration_set`을 `val` 또는 `test`로 설정할 때 자동으로 수행됩니다.
또한, 이 튜토리얼을 통해 Lightning 트레이너를 사용하지 않고도 데이터 모듈을 사용하는 방법과 TorchUncertainty의 모델을 사용하는 방법도 살펴봅니다.
1. Loading the Utilities
이 튜토리얼에서는 다음의 유틸리티가 필요합니다:
- TorchUncertainty의 Calibration Error 지표를 사용하여 ECE(Expected Calibration Error)로 top-label 캘리브레이션을 평가하고, 신뢰도 다이어그램을 그리기 위한 도구
- 데이터를 처리하기 위한 CIFAR-100 데이터 모듈
- 시작 모델로 사용할 ResNet 18
- Top-label 캘리브레이션을 개선하기 위한 Temperature Scaler
- Hugging Face 모델을 쉽게 다운로드하기 위한 유틸리티 함수
만약 분류 루틴을 사용하는 경우, `log_plots` 플래그를 사용하면 텐서보드 로그에서 자동으로 플롯을 확인할 수 있습니다.
from torch_uncertainty.datamodules import CIFAR100DataModule
from torch_uncertainty.metrics import CalibrationError
from torch_uncertainty.models.resnet import resnet
from torch_uncertainty.post_processing import TemperatureScaler
from torch_uncertainty.utils import load_hf2. Loading a model from TorchUncertainty’s HF
CIFAR-100에서 모델을 처음부터 훈련하는 대신, Hugging Face에서 사전 훈련된 모델을 로드할 수 있습니다. 이를 통해 시간을 절약할 수 있으며, 간단한 한 줄의 코드로 모델을 불러올 수 있습니다:
# Build the model
model = resnet(in_channels=3, num_classes=100, arch=18, style="cifar", conv_bias=False)
# Download the weights (the config is not used here)
weights, config = load_hf("resnet18_c100")
# Load the weights in the pre-built model
model.load_state_dict(weights)3. Setting up the Datamodule and Dataloaders
데이터 모듈에서 데이터로더를 가져오려면 `prepare_data`와 `setup` 메서드를 호출한 후, 테스트 데이터로더 리스트의 첫 번째 요소를 추출하면 됩니다. 만약 `eval_ood` 파라미터가 `True`로 설정된 경우, 리스트에는 in-distribution과 out-of-distribution data와 data loader가 포함되어 여러 요소가 있을 수 있습니다. 그렇지 않으면, 리스트에는 하나의 요소만 포함됩니다.
dm = CIFAR100DataModule(root="./data", eval_ood=False, batch_size=32)
dm.prepare_data()
dm.setup("test")
# Get the full test dataloader (unused in this tutorial)
dataloader = dm.test_dataloader()[0]4. Iterating on the Dataloader and Computing the ECE
먼저, 원래의 테스트 세트를 캘리브레이션 세트와 테스트 세트로 나누어 정확한 평가를 진행합니다.
ECE을 계산할 때는 입력과 연관된 확률을 제공해야 합니다. 이를 위해 PyTorch의 `softmax` 함수를 호출하면 됩니다.
또한, GPU 없이 오래 걸리는 계산을 피하기 위해, 캘리브레이션 계산은 테스트 세트의 일부만을 대상으로 제한합니다.
from torch.utils.data import DataLoader, random_split
# Split datasets
dataset = dm.test
cal_dataset, test_dataset, other = random_split(
dataset, [1000, 1000, len(dataset) - 2000]
)
test_dataloader = DataLoader(test_dataset, batch_size=32)
# Initialize the ECE
ece = CalibrationError(task="multiclass", num_classes=100)
# Iterate on the calibration dataloader
for sample, target in test_dataloader:
logits = model(sample)
probs = logits.softmax(-1)
ece.update(probs, target)
# Compute & print the calibration error
print(f"ECE before scaling - {ece.compute():.3%}.")ECE before scaling - 9.194%.우리는 또한 top-label 캘리브레이션(Top-label Calibration) 그림을 계산하고 플로팅합니다. 이를 통해 모델이 잘 캘리브레이션되지 않았음을 확인할 수 있습니다.
fig, ax = ece.plot()
fig.show()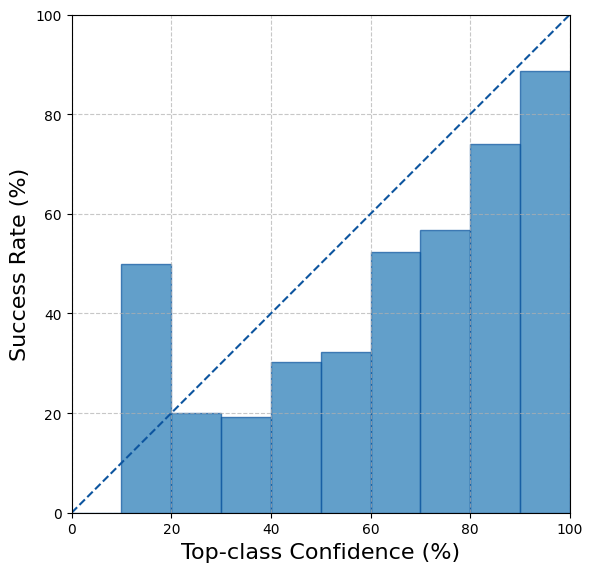
5. Fitting the Scaler to Improve the Calibration
TemperatureScaler는 소프트맥스의 스케일링을 조정할 수 있는 하나의 파라미터를 가지고 있습니다. 우리는 이 파라미터를 조정하여 캘리브레이션 세트에서 tempered cross-entropy를 최소화합니다. 여기서 캘리브레이션 세트는 테스트 세트의 일부로 정의되며, 1000개의 데이터를 포함합니다. 자세한 내용은 TemperatureScaler의 `fit` 메서드에서 실행되는 코드를 참고하세요.
# Fit the scaler on the calibration dataset
scaled_model = TemperatureScaler(model=model)
scaled_model.fit(calibration_set=cal_dataset)6. Iterating Again to Compute the Improved ECE
스케일러를 직접 캘리브레이션된 모델로 사용할 수 있습니다.
이때, 이전과 현재 반복에서의 점수가 섞이지 않도록 ECE 지표를 먼저 리셋해야 한다는 점에 유의하세요.
# Reset the ECE
ece.reset()
# Iterate on the test dataloader
for sample, target in test_dataloader:
logits = scaled_model(sample)
probs = logits.softmax(-1)
ece.update(probs, target)
print(f"ECE after scaling - {ece.compute():.3%}.")ECE after scaling - 4.372%.마지막으로, 스케일링된 top-label 캘리브레이션 그림을 계산하고 플로팅합니다. 이제 모델이 이전보다 더 잘 캘리브레이션된 것을 확인할 수 있습니다.
fig, ax = ece.plot()
fig.show()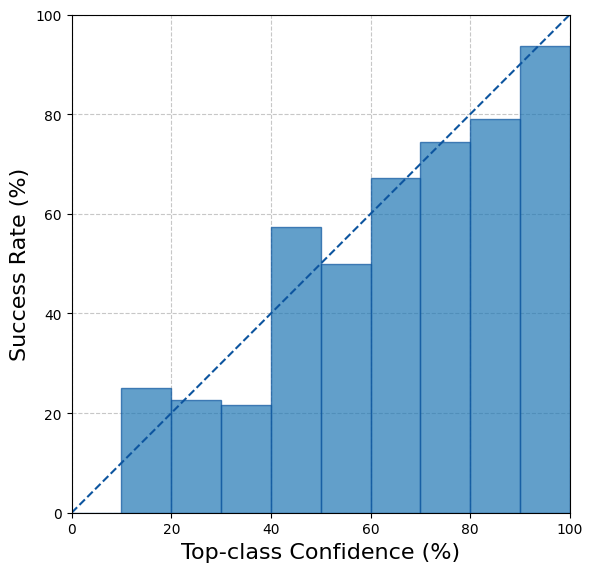
Note
Temperature Scaling은 캘리브레이션 세트가 테스트 세트를 잘 대표할 때 매우 효과적입니다. 이러한 경우, 우리는 캘리브레이션 세트와 테스트 세트가 동일한 분포에서 추출되었다고 말합니다. 그러나 실제 환경에서는 데이터셋이 변화할 수 있기 때문에 이러한 가정이 항상 성립하지 않을 수 있습니다.
출처
Improve Top-label Calibration with Temperature Scaling — TorchUncertainty 0.2.1.post0 documentation
Improve Top-label Calibration with Temperature Scaling In this tutorial, we use TorchUncertainty to improve the calibration of the top-label predictions and the reliability of the underlying neural network. This tutorial provides extensive details on how t
torch-uncertainty.github.io
Expected Calibration Error: Naeini, M. P., Cooper, G. F., & Hauskrecht, M. (2015). Obtaining Well Calibrated Probabilities Using Bayesian Binning. In AAAI 2015.
Temperature Scaling: Guo, C., Pleiss, G., Sun, Y., & Weinberger, K. Q. (2017). On calibration of modern neural networks. In ICML 2017.
'통계 & 머신러닝 > 통계적 머신러닝' 카테고리의 다른 글
| [Torch Uncertainty] Tutorial: Training a LeNet with Monte Carlo Batch Normalization (0) | 2024.08.22 |
|---|---|
| [Torch Uncertainty] Tutorial: Training a LeNet with Monte-Carlo Dropout (0) | 2024.08.22 |
| [Torch Uncertainty] Quick Start (0) | 2024.08.22 |
| [Torch Uncertainty] Installation (0) | 2024.08.22 |
| [논문] On Calibration of Modern Neural Networks: Results (0) | 2024.08.20 |